
トラブルシューティング力が求められる理由

なぜ問題解決力はエンジニアだけでなく、ビジネス全般に必要か
トラブルシューティングと聞くと、エンジニアやシステム担当者の仕事だと思われがちですが、実はすべてのビジネスパーソンに求められるスキルです。例えば、プロジェクトの進行が遅れる原因を特定したり、取引先とのコミュニケーション不具合を解消したりと、「問題を特定し、正確に対応する力」はあらゆるシーンで役立ちます。
特にITを活用する現代のビジネスでは、システムトラブルやデータ管理の問題は日常茶飯事です。たとえば、ある日突然「システムにアクセスできない」という問題が発生した場合、原因がネットワークなのか、認証システムなのか、サーバーのトラブルなのかを素早く見極める必要があります。ここで正しいトラブルシューティングのプロセスを理解しているかどうかで、対応スピードと正確性に大きな差が生まれます。
トラブル対応の早さと正確さが仕事の成果を大きく左右する
トラブル対応においては、「いかに早く、いかに正確に」対応できるかが成果に直結します。

例えば、ECサイトの決済システムが停止した場合、対応の早さが売上に直結します。しかし、原因を正確に突き止めずにただ再起動を繰り返すだけでは、同じ問題が再発し続け、結果的に顧客離れにつながる可能性もあります。
「再現性のある解決力」を身につけるためのプロセスを学ぶ
「再現性のある解決力」とは、どんなトラブルにも対応できる共通のプロセスを持つことです。経験や勘だけに頼るのではなく、誰でも同じ手順を踏むことで正確な原因特定と解決ができる方法を身につけることが、持続可能なスキルアップにつながります。
本記事では、エンジニアの現場で培われた「鉄板プロセス」を解説します。ITトラブルだけでなく、日常業務の課題解決にも応用できるので、ぜひ最後までお付き合いください。
トラブルシューティングの鉄板プロセス

エンジニアがトラブル対応をする際、「どこから手をつけたらいいかわからない」という状況に陥ることは少なくありません。
トラブルシューティングにはいくつかの原則がありますが、特に大事なのは「再現性のあるプロセス」を持つこと。この鉄板プロセスを身につければ、ITシステムだけでなく、ビジネスシーンのさまざまな課題解決にも応用できます。
今回はその第一歩となる「現象の正確な把握」について、詳しく見ていきましょう。
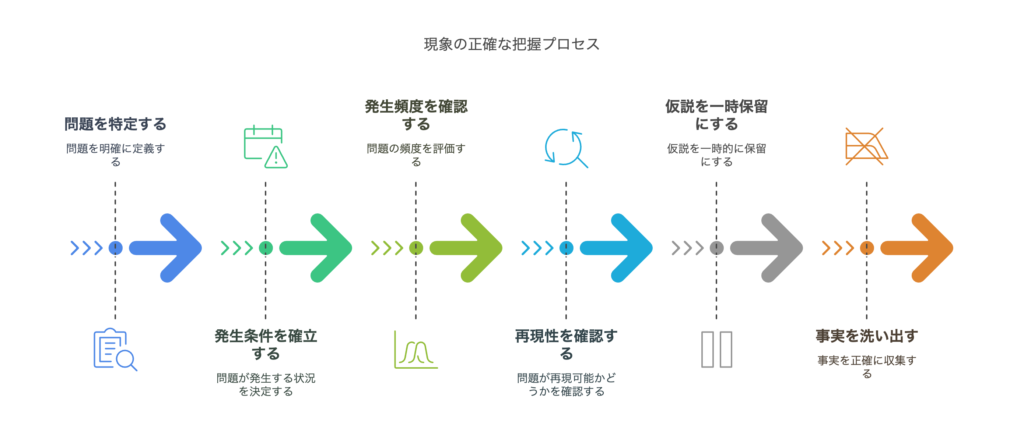
【ステップ1】現象の正確な把握(事実と仮説を切り分ける)
トラブルシューティングにおける最初のステップは、「何が起きているのか?」を正確に言語化することです。ここを曖昧にしたまま対応を始めると、見当違いの仮説に振り回されたり、不要な作業に時間を費やしたりすることになります。
たとえば、あなたがクラウド移行プロジェクトの中で「アプリケーションが動かない」という報告を受けたとしましょう。ここでやってしまいがちなのが、「サーバーの設定が悪いのでは?」や「ネットワークが不安定かも?」と、いきなり仮説ベースで動いてしまうこと。
でも、ちょっと待ってください。そもそも「動かない」とはどういう状態でしょうか?エラーメッセージは?すべてのユーザーで発生している?一部の機能だけ?まずは事実を正確に洗い出すことが大前提です。
問題は何か?症状を正確に言葉にする
まずは、発生している現象をできる限り具体的に表現しましょう。
ポイントは、「何が、どのように、どんな条件で起きているか」を正確に表現することです。
発生条件(いつ、どこで、誰が、何をしたときに)
次に、発生条件を明確にしましょう。以下の視点で情報を整理します。
- いつ: トラブルが初めて発生した日時、頻度
- どこで: どの環境(本番、検証、ローカル)、どのシステム、どの機能か
- 誰が: 特定のユーザーのみか、全ユーザーか、管理者か、一般ユーザーか
- 何をしたときに: どの操作をしたときにエラーが発生するか、特定のデータを入力したときか
「本番環境にて、2025年2月26日 10:00 以降、特定の管理者ユーザーが ‘ユーザー一覧’ 画面を表示しようとすると ‘504 Gateway Timeout’ エラーが発生する」
ここまで具体的に特定できれば、原因の絞り込みが格段に早くなります。
発生頻度や再現性の確認
発生頻度や再現性も、原因特定における重要なヒントになります。
- 発生頻度: 毎回発生するのか、時々なのか、一度だけなのか
- 再現性: 特定の条件下で必ず再現するのか、ランダムに発生するのか
仮説は一旦脇に置き、目の前の事実を正確に洗い出す
トラブル対応において、早く原因を見つけたいという焦りから、つい仮説を先行させがちです。ですが、最初の段階では仮説は一旦脇に置くのが鉄則です。
「ネットワークが怪しい」「サーバー設定がおかしいかも」といった憶測は、事実が揃ってから立てるべきです。事実を正確に把握せずに仮説を立てると、無駄な調査に時間を浪費し、問題の本質を見落とすリスクが高まります。
事実の洗い出しシート(例):
| 項目 | 内容 |
|---|---|
| 発生日時 | 2025年2月26日 10:00 |
| 発生環境 | 本番環境 |
| 発生ユーザー | 管理者ユーザーのみ |
| 発生画面 | ユーザー一覧画面 |
| エラーメッセージ | ‘504 Gateway Timeout’ |
| 発生頻度 | 毎回発生 |
| 再現性 | 同条件で必ず再現 |
このように、仮説を交えず事実だけを並べることで、冷静かつ正確な状況把握が可能になります。
ステップ1のまとめ
「現象の正確な把握」は、トラブルシューティングの出発点です。このステップが曖昧だと、原因特定も解決も遠回りになってしまいます。
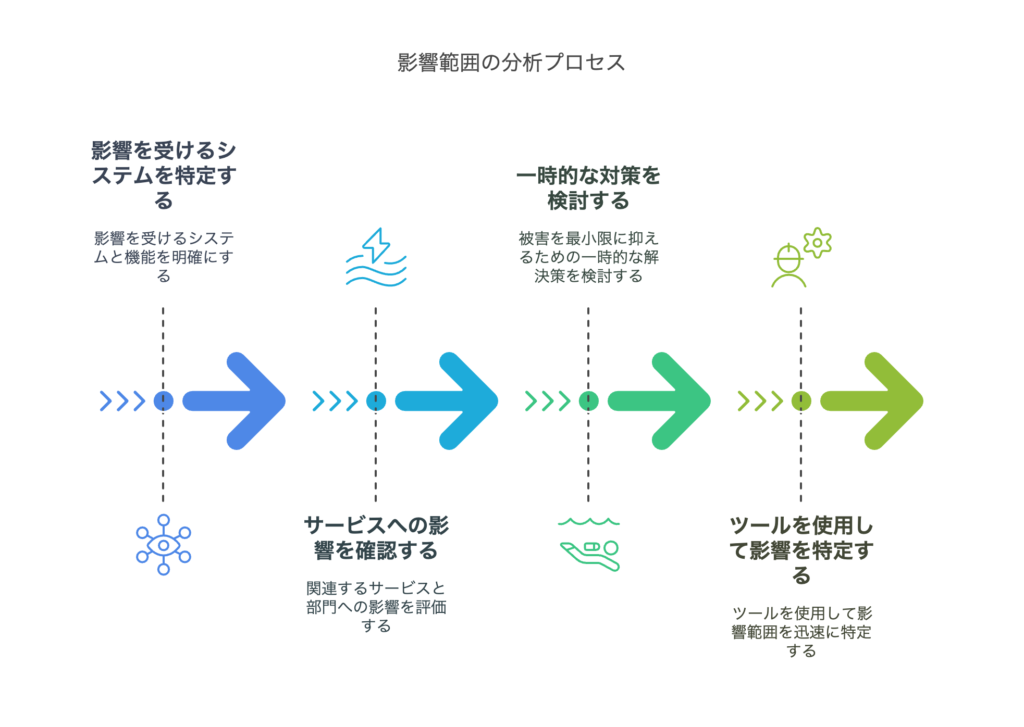
【ステップ2】影響範囲の特定(どこまで問題が広がっているか)
トラブルシューティングの第一ステップ「現象の正確な把握」で、「何が起きているのか?」を明確にしたら、次は「どこまで問題が広がっているか?」を特定することが重要です。
このステップを飛ばしてしまうと、見えないところで問題が拡大していることに気づかず、対応が後手に回る可能性があります。特にシステム障害や業務トラブルでは、影響範囲の見極めが初動対応の質を大きく左右します。
今回は、影響範囲を正確に特定するためのポイントと具体的な手順について解説します。
どのシステム・機能に影響があるのか
まずは、トラブルの影響を受けている範囲を正確に把握しましょう。これはITシステムに限らず、業務プロセスや関係者への影響にも応用できる視点です。
例えば、クラウド移行中のシステムで「ユーザー管理画面が表示されない」という問題が発生したとします。このとき、次のような視点で影響範囲を絞り込んでいきます。
関連する他のサービスや部署への影響確認
問題の発生源が特定のシステムや機能に限定されているように見えても、その問題が他のサービスや部署に波及していないか確認することが重要です。特に、クラウド移行プロジェクトのように複数のシステムが連携している環境では、影響範囲は広がりやすくなります。
被害を最小限に抑えるための一時的な対応策
影響範囲を特定したら、被害を最小限に抑えるための一時対応を検討しましょう。根本解決には時間がかかる場合もあるため、「まずは業務を継続できる状態にする」ことが重要です。
影響範囲の特定に役立つツールと方法
システムトラブルの場合、ツールを活用して影響範囲を迅速に特定することが重要です。
ツールを用いた切り分けステップ:
ログを確認し、エラーメッセージと発生タイミングを特定
モニタリングツールでリソース状況を確認(CPU、メモリ、ネットワーク負荷など)
ネットワーク疎通を確認し、通信経路の問題を切り分け
ステップ2のまとめ
「影響範囲の特定」は、トラブルシューティングのスピードと正確性を左右する重要なステップです。ここを丁寧に行うことで、「どこに優先的に対応すべきか?」が明確になり、限られたリソースを効率的に活用できます
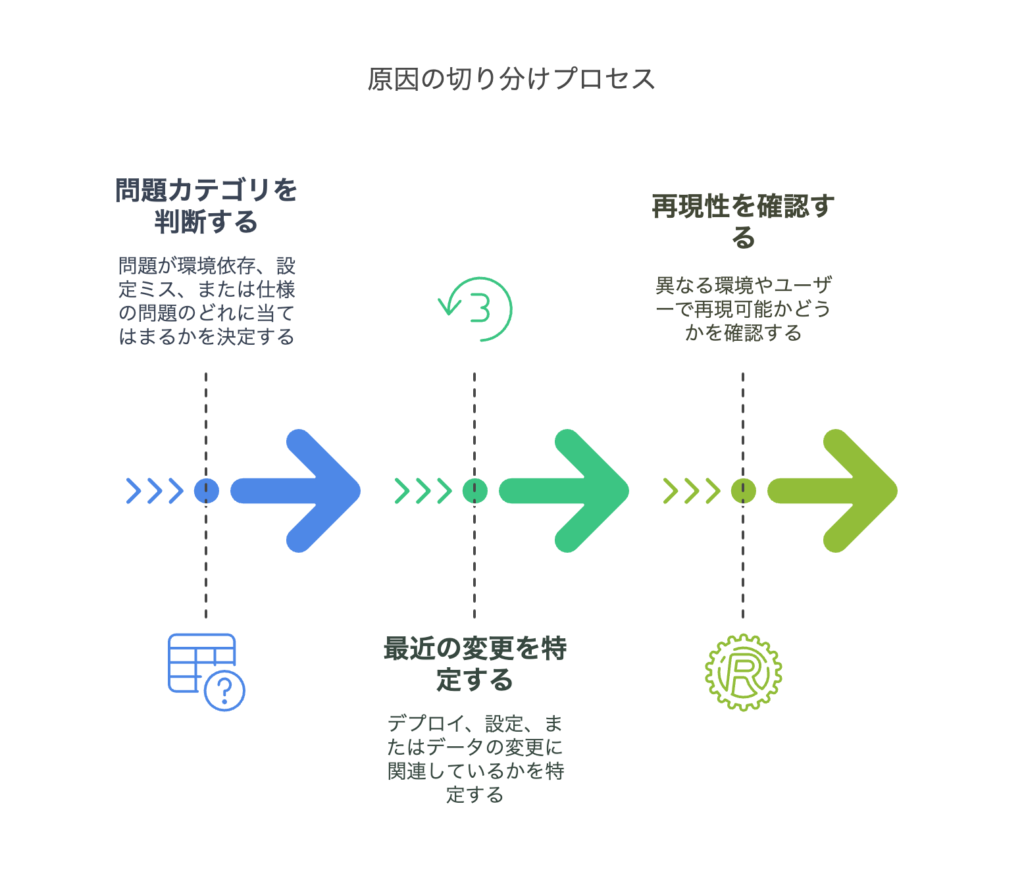
【ステップ3】原因の切り分け(どこに問題があるのか)
前回のステップで「どこまで問題が広がっているか?」を特定しました。次に必要なのは、「なぜ問題が発生しているのか?」を明らかにすることです。
原因を正しく特定しないと、場当たり的な対処に終始し、同じ問題が繰り返し発生するリスクがあります。そこで、このステップでは問題の発生要因を論理的に切り分け、根本原因を突き止めるプロセスを解説します。
環境依存か、設定ミスか、仕様の問題か
まずは、問題の原因がどのカテゴリに属するのかを大まかに分類しましょう。
トラブルの原因は、大きく以下の3つに分けられます。
| カテゴリ | 特徴 | 具体例 |
|---|---|---|
| 環境依存 | 特定の環境(本番/検証、OS、ブラウザ)でのみ発生 | ローカルでは動くが、サーバーではエラーになる |
| 設定ミス | 設定の誤りや不備が原因で問題が発生 | IP制限が誤っていてアクセスできない |
| 仕様の問題 | そもそも設計や仕様上の制約がある | 大量データを処理するとタイムアウトする |
例えば、「特定のブラウザでボタンが動作しない」という問題が発生した場合、環境依存の可能性が高いです。一方、「管理画面にログインできない」場合は、設定ミス(アクセス制御や認証設定)が疑われます。
まずは、どのカテゴリに属する可能性が高いかを判断し、次のアクションを決めていきます。
「変更点」を探す(直前の作業やアップデート、設定変更)
多くのトラブルは、「何かを変更した直後」に発生します。そのため、問題が発生する直前に行われた変更点を特定することが重要です。
このように、「何を変えたか?」を把握することで、原因特定のスピードが大幅に向上します。
同じ条件で発生するか、他の環境で再現するかテスト
問題の再現性を確認することは、原因を切り分ける上で極めて重要です。「特定の条件でのみ発生する」のであれば、その条件を特定することで問題の原因に迫ることができます。
このように、「再現性の有無」を確認することで、問題の切り分けがしやすくなります。
ステップ3のまとめ
原因の切り分けは、トラブルシューティングの中核です。場当たり的な対応を避け、論理的に問題の発生源を特定することで、迅速かつ正確な解決が可能になります。
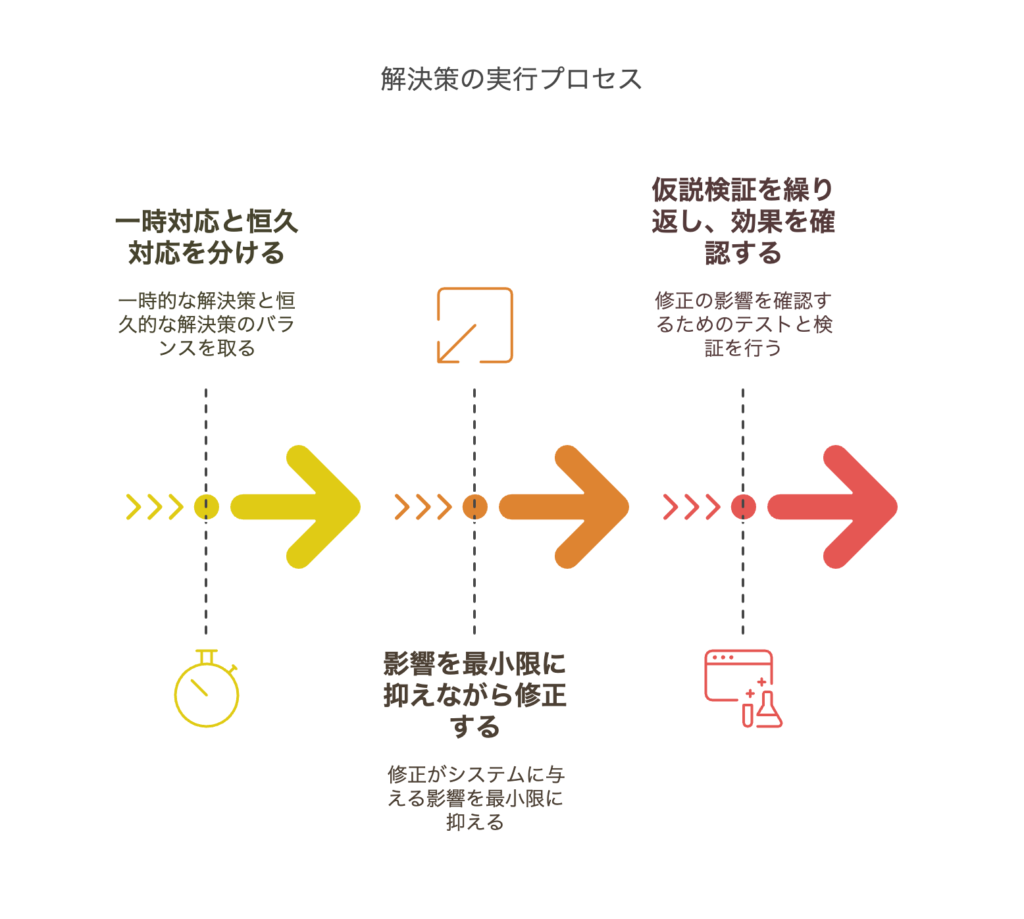
【ステップ4】解決策の実行(迅速かつ正確に)
原因を特定したら、次は「どう解決するか?」を考える段階です。トラブル対応では、焦って場当たり的な修正を行うと、かえって状況を悪化させるリスクがあります。そのため、影響を最小限に抑えながら、確実に問題を解決するアプローチが求められます。
本ステップでは、迅速かつ正確な問題解決のためのプロセスを解説します。
一時対応と恒久対応を分けて考える
問題が発生すると、すぐにでも復旧させる必要があるケースが多くあります。しかし、根本原因を取り除くのには時間がかかる場合もあります。そこで、トラブル対応では「一時対応」と「恒久対応」を分けることが重要です。
・サーバーがダウン → フェールオーバーで別のサーバーに切り替え
・アクセス障害 → キャッシュを使って静的ページを表示
・不具合のある機能 → 一時的に利用を停止し、周知する
・負荷によるサーバーダウン → 負荷分散設計を見直す
・バグが原因のエラー → ソースコードの修正とテストの強化
・ヒューマンエラーによる障害 → 運用プロセスを改善し、自動化を導入
このように、「短期的な応急処置」と「長期的な根本解決」を明確に分けることで、スムーズなトラブル対応が可能になります。
影響範囲を最小限にしつつ、安全に修正する方法を選択
問題の修正を行う際は、影響範囲をできるだけ限定し、安全に対応する方法を選ぶことが重要です。
特に本番環境の修正では、変更が新たな問題を引き起こさないかを慎重に確認しながら進めることが重要です。
仮説検証を繰り返し、効果を確認しながら対応
問題解決では、「修正したら終わり」ではなく、修正が本当に有効だったのかを確認するプロセスが必要です。
このように、「修正 → 効果測定 → 再調整」のサイクルを回すことで、確実な問題解決につながります。
ステップ4のまとめ
解決策を実行する際に重要なのは、「いきなり大きな変更をせず、小さく試しながら安全に進める」ことです。
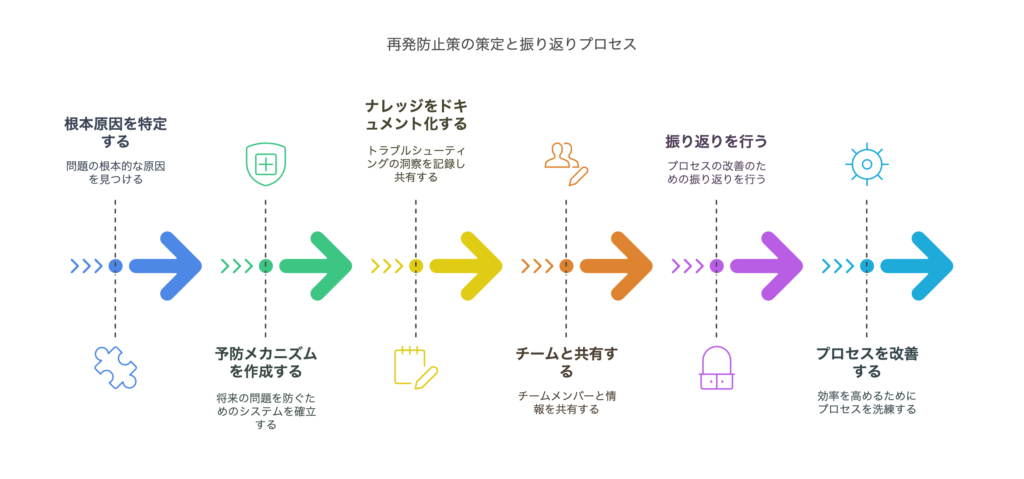
【ステップ5】再発防止策の策定と振り返り
問題を解決したら、それで終わりではありません。「同じ問題を繰り返さない」ための対策を講じることが、優れたエンジニアやビジネスパーソンの真価です。トラブル対応には時間とコストがかかるため、再発防止策をしっかり整備することで、将来的なリスクを削減できます。
本ステップでは、根本原因の特定・ナレッジ共有・プロセス改善という3つのポイントを軸に、効果的な振り返りの方法を解説します。
根本原因を特定し、同じ問題を起こさないための仕組みづくり
トラブル対応で最も避けるべきなのは、「一時的な対応だけして、また同じ問題が発生すること」です。再発防止のためには、問題の本質を見極め、根本的な解決策を導き出すことが重要になります。
再発防止のためには、「なぜ?」を繰り返して問題の本質に迫ることが重要です。これには「なぜなぜ分析(5 Whys)」が効果的です。
このように、表面的な原因ではなく、真因を突き止めることが再発防止の鍵です。
ドキュメント化とナレッジ共有
問題が発生した際に、対応した人だけが知っている状態では、組織としての成長につながりません。そのため、対応内容を記録し、チーム全体で共有することが重要になります。
これを「ナレッジベース(KB)」や「障害管理シート」に記録し、チームで共有すると、同じ問題が発生した際に迅速に対応できるようになります。
ドキュメント化の具体例
| 項目 | 内容 |
|---|---|
| 発生日時 | 2025/02/20 15:30 |
| 発生事象 | APIレスポンスが異常に遅延 |
| 影響範囲 | フロントエンドのユーザー操作全般 |
| 原因 | DBインデックス不足によるクエリ遅延 |
| 対応策 | 一時対応:キャッシュ適用、恒久対応:インデックス最適化 |
| 再発防止策 | コードレビュー時にクエリパフォーマンスチェックを追加 |
このようにフォーマット化することで、情報が整理され、他のメンバーが素早くキャッチアップできるようになります。
振り返りを行い、プロセスや体制に改善点がないか検討
問題が発生した後は、「なぜこの問題が起きたのか?」、「今後どうすればより良い対応ができるか?」をチームで振り返ることが重要です。
GoogleやAWSなどの大手IT企業では、障害発生後に「ポストモーテム(事後分析)」を実施しています。
ポストモーテムでは、個人の責任を追及せず、「仕組みの改善」にフォーカスすることが重要です。
振り返りを通じて、チームの対応力を向上させることで、次回のトラブル対応がよりスムーズになります。
ステップ5のまとめ
再発防止策の策定と振り返りは、単なる「後処理」ではなく、組織の成長につながる重要なプロセスです。
トラブル対応は、エンジニアやビジネスパーソンにとって避けられない業務の一つですが、適切なプロセスを整えれば、対応力が向上し、よりスマートな問題解決が可能になります。
「問題が発生しても、慌てずに冷静に対処し、改善につなげる」ことができれば、エンジニアとしてのスキルアップはもちろん、チームや組織全体の成長にも貢献できます。
トラブル対応を効率化するためのツールとスキル

システムトラブルが発生した際、迅速に原因を特定し、適切な対応を取ることが求められます。しかし、「どこから調査すればいいのかわからない」、「情報共有がうまくいかず対応が遅れる」 という課題に直面することも少なくありません。
エンジニアがスムーズにトラブルシューティングを行うためには、適切なツールの活用と必要なスキルの習得が不可欠です。本記事では、トラブル対応の効率を大幅に向上させるための3つの重要ポイントを解説します。
ログ解析ツール、監視システムの活用
システムトラブルの原因を特定する際、ログの解析とリアルタイム監視は欠かせません。トラブルの発生地点や影響範囲をすばやく特定することで、対応時間を大幅に短縮できます。
ログ解析ツールの活用
ログはシステムの「証拠」そのもの。適切なログを取得・分析できれば、問題の発生原因を効率的に特定できます。
こうしたログ解析により、「特定のSQLクエリの実行時間が異常に長い」→「データベースのインデックスが不足している」 といった根本原因を突き止めることができます。
監視システムの活用
リアルタイムでシステムの状態を監視することで、トラブルを未然に防ぐことが可能です。
ログ解析と監視を組み合わせることで、「障害の予兆を検知し、未然に防ぐ」 ことも可能になります。
コミュニケーションスキル(状況報告、関係者調整)
トラブル対応では、技術力だけでなく、適切なコミュニケーションも求められます。対応状況を適切に共有しないと、二次被害の拡大や無駄な調査作業が発生してしまいます。
状況報告のポイント
トラブル発生時は、以下のフレームワークを使って報告すると、状況が明確になります。
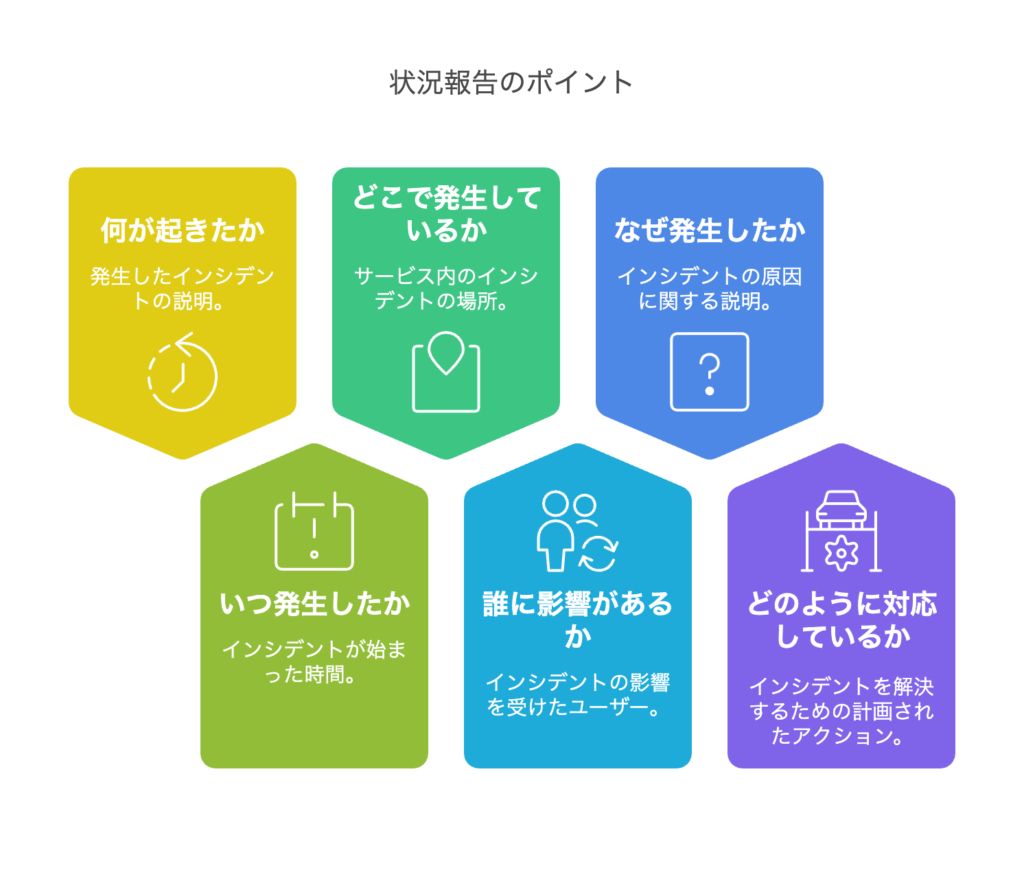
このように簡潔かつ具体的に報告することで、関係者の意思決定がスムーズになり、無駄なやりとりを減らせます。
ドキュメント作成力(議事録、報告書、ナレッジベース)
トラブル対応後に、「対応内容を記録せずに終わってしまい、後から同じ問題が発生しても対処できない」というケースはよくあります。
これを防ぐために、トラブル対応の知見をドキュメント化し、ナレッジとして蓄積することが重要です。
ナレッジベースを活用する
対応内容をWiki、Notion、Confluenceなどのナレッジベースに記録し、チーム全体で共有しましょう。また、JIRAやRedmineのようなタスク管理ツールに記録するのも有効です。
トラブル対応を効率化するためのポイント
トラブル対応を効率化するためには、技術スキルとビジネススキルを組み合わせることが不可欠です。
適切なツールとスキルを身につけることで、「トラブルが発生しても冷静に対応できるエンジニア」 へと成長できます。トラブルをチャンスに変えるスキルを磨いていきましょう!
トラブル対応で“信頼される人”になるために

トラブル対応は、システムの安定運用を支える重要な業務のひとつです。しかし、単に問題を解決するだけではなく、「この人なら安心して任せられる」と思われることが、エンジニアとしての評価やキャリアアップにつながります。
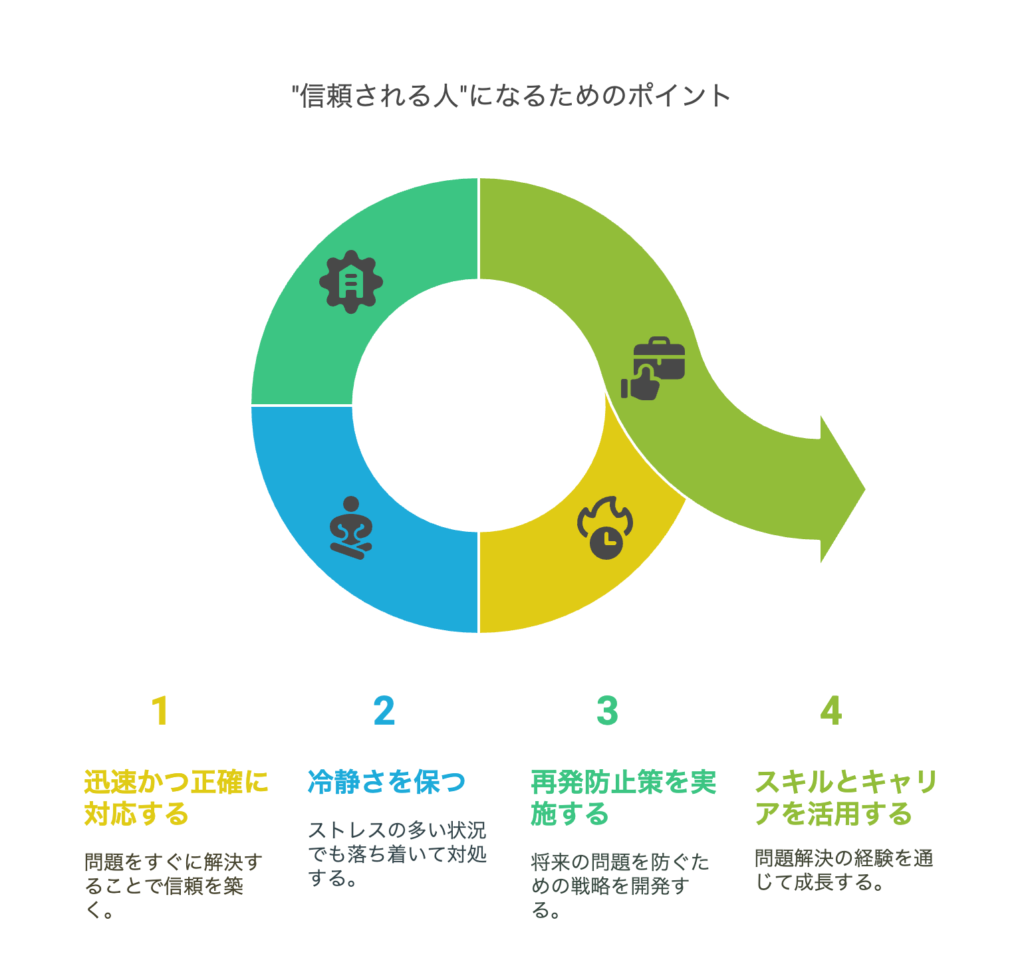
では、どのようにすればトラブル対応を通じて“信頼される人”になれるのでしょうか? ここでは、迅速かつ正確な対応、冷静な対処姿勢、再発防止と改善提案の3つのポイントを解説します。
迅速かつ正確な対応が評価につながる
トラブル対応では、スピードと正確さが最も重要視されます。対応が遅れると、システムのダウンタイムが長引き、ビジネスに大きな影響を与えてしまうためです。
「とりあえず動かす」はNG!正しい手順で対応する
焦るあまり、場当たり的な対応をしてしまうのは危険です。たとえば、以下のような例があります。
「この人に任せれば大丈夫」と思われるためには、目先の回避策ではなく、再発しない対応を意識することが重要です。
感情的にならず冷静に対処する姿勢
トラブルが発生すると、現場は混乱しやすく、プレッシャーもかかります。 特に、大規模障害や影響範囲が広い問題では、周囲からの問い合わせが殺到し、精神的な負担も増します。
冷静さが信頼を生む
トラブル時に信頼される人は、どんな状況でも冷静に対応できる人です。感情的にならず、客観的な視点を持ち、冷静に状況を判断できるエンジニアは、周囲から高く評価されます。
たとえば、こんなシーンを想像してください。
このように、冷静に状況を整理し、対応の方向性を示せる人は「頼れる存在」として認識されます。
冷静な対応をするためのポイント
- すぐに結論を出そうとしない(まずは情報収集)
- 関係者と協力する(チームで対応する意識を持つ)
- プレッシャーを言語化する(「焦る気持ちはあるが、まずは事実を整理する」)
再発防止と改善提案で「問題解決力」を発揮
トラブルが解決した後、再発防止策を考え、改善提案を行うことで「問題解決力」が評価されます。 これは、単なる「火消し役」ではなく、「トラブルを減らす仕組みを作れる人」として信頼を得るための重要なポイントです。
再発防止のための3ステップ
根本原因を特定する
-「なぜこのトラブルが発生したのか?」を深掘り
– ログや監視データを分析し、発生原因を特定
恒久的な対策を考える
– 例えば、「手動操作が原因なら自動化」、「監視体制が甘いならアラートを強化」など
– 技術的な改善だけでなく、運用の見直しも検討
ナレッジを共有する
– 再発防止策や対応手順をドキュメント化し、チームで共有
– 社内Wiki、Notion、Confluenceなどを活用
「改善提案」を行うことで評価が上がる
たとえば、以下のような改善提案ができると、「この人は単なる技術者ではなく、業務全体を考えられる人だ」と評価されます。
こうした取り組みを積み重ねることで、「この人がいるからトラブルが減る」という信頼を築くことができます。
トラブル対応で“信頼される人”になるためのポイント
トラブル対応は、一時的な問題解決にとどまらず、エンジニアとしての評価を大きく左右する業務です。
トラブル対応を「ただの業務」と捉えるのではなく、自身のスキルアップやキャリアに活かすチャンスと考えることが重要です。
「トラブルが発生しても、この人がいれば安心」 そう思われるエンジニアを目指し、日々の業務に取り組んでいきましょう!
まとめ:鉄板プロセスを武器に、確実な問題解決を

トラブルシューティングは、ただ単に問題を解決する作業ではなく、「いかに効率よく、確実に解決へと導くか」が問われるスキルです。そして、その差を生むのは事前の準備と正しいプロセスの実践です。
これまで紹介してきた鉄板プロセスを武器にすることで、エンジニアとしてのスキル向上はもちろん、ビジネス全般に応用できる「問題解決力」を鍛えることができます。最後に、トラブル対応における重要なポイントを振り返りながら、実践へのヒントをお伝えします。
トラブル対応は「準備」と「プロセス」で差がつく
トラブル対応の優劣を分ける要素は、事前準備とプロセスの徹底です。
事前準備の重要性
トラブルが起こってから対応方法を考えるのではなく、日頃からの準備がカギを握ります。
こうした事前準備があることで、トラブル発生時に焦ることなく冷静に対応できるようになります。
鉄板プロセスを守る
感覚や経験に頼った場当たり的な対応ではなく、「迷ったらこの順番」を意識して確実に解決へと進めることが大切です。
このプロセスを徹底することで、どんなトラブルにも冷静に対応できる力が身につきます。
システムトラブルだけでなく、ビジネス全般に応用できるスキル
トラブル対応で培われるスキルは、エンジニア業務だけでなく、ビジネス全般にも活かせる普遍的な能力です。
たとえば、エンジニアでなくても、クレーム対応や業務改善の場面で、トラブルシューティングの考え方は大いに役立ちます。
つまり、トラブル対応を通じて「問題解決力」を磨くことで、どんな職種・業務においても価値のあるスキルを身につけることができるのです。
鉄板プロセスを実践し、信頼されるエンジニアへ
トラブル対応は、ただの「作業」ではなく、エンジニアとしての評価やキャリアに大きな影響を与えるスキルです。
トラブル対応で信頼される人になるために
この鉄板プロセスを実践し続けることで、トラブル対応のスキルは確実に向上し、周囲からの信頼も得られるようになります。
「迷ったらこの順番!」を合言葉に、確実な問題解決を目指していきましょう!
以上、「迷ったらこの順番!エンジニア直伝・トラブルシューティングの鉄板プロセス」の話題でした。








